Using custom Loras to make videos with ComfyUI

The release of Hunyuan Video last month is a big milestone for AI video generation. With 13 billion parameters, it is the most powerful open-source video generation model to date and offers the likes of Runway's Gen 3 a run for their money. What makes this development particularly interesting is that the community was quick to implement Lora training for Hunyuan Video, opening a world of possibilities for AI creators. In this guide, we will show you how to set up and run Hunyan Video with Loras on ComfyUI.
To get started you will need to install the VideoHelperSuite and HunyuanVideoWrapper node packs, both of which are available through the ComfyUI manager.
You will also need to download the following models:
- Hunyuan video to the “ComfyUI/models/diffusion_models” folder
- The two text encoder models, here and here, to the “ComfyUI/models/text_encoders” folder
- And the VAE model to “ComfyUI/models/vae”
You can then add your own Hunyuan LoRAs to the “ComfyUI/models/loras”, or use the ones created by the community on civit.ai. In this guide, we used the Studio Ghibli LoRA from seruva19.
To load the workflow, you can simply drag and drop the following image to ComfyUI. (If you are having problems, sometimes it helps to open the video in a new tab first).

Once everything is loaded, you can start using the workflow right away. Most of the parameters are better left as they are. But here are the key ones for those of you who want to experiment:
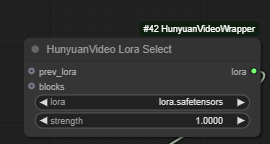
HunyuanVideo Lora Select
This is where you can select the LoRA and set its strength. If you set the strength to 0, the LoRA will be ignored during the generation process. And if you set it to 1, you will maximise its influence on the final output. Usually, the best value is somewhere between the two.
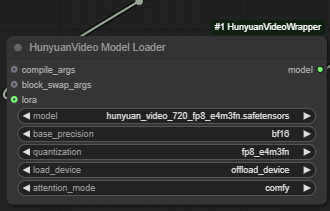
HunyuanVideo Model Loader
This is the node responsible for loading the Hunyuan video model. We recommend using the bf16 version, which is linked at the start of the tutorial, but they also have an fp8 model available. This second option is a bit smaller and will take a less space on your GPU at the expense of lower output quality.
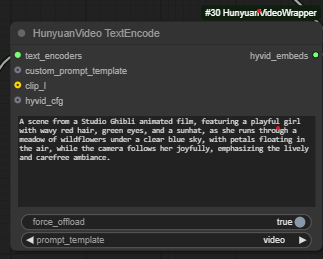
HunyanVideo TextEncode
This is where you can set the prompt for your video. This format usually works well: “[Subject Description], [Action Description], [Scene Description], [Style Description], [Quality Requirements]”
HunyanVideo Sampler
This node is where the video generation happens. You can use the width and height parameters to set the dimensions of your video. The other important parameter is num_frames, which lets you select how many frames you want in total.
These are the recommended settings for Hunyuan video (width x height x num_frames):
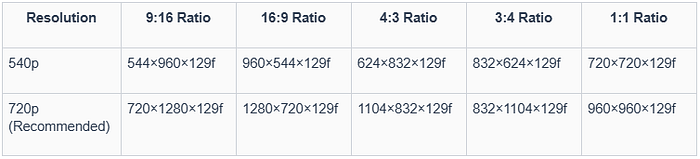
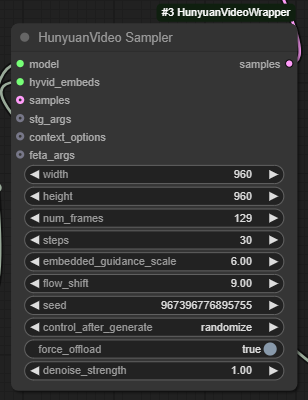
This workflow works on GPUs with a minimum of 45GB VRAM for 544p×960p×129 frames videos. For larger video or for maximum quality we recommend using a GPU with 80GB VRAM. If you don't have the right hardware or you want to skip the installation process, you can use our template or upload your own workflow to ViewComfy cloud and access it via a ViewComfy app, an API or the ComfyUI interface.